An interesting exploit was published at BlackHat 2019 this year by Portswigger’s James Kettle. It is interesting because of the implications to several things I am working on regarding reverse proxies as well as my experience working with CDNs.
The summary of the exploit is that the HTTP standard allows two conflicting header fields that are used to define the behavior of multiple requests sent in sequence to exist within a single request, transfer-encoding and content-length. When a request comes in with both fields, the default behavior is to ignore the latter. (RFC 2616)
The exploit occurs when there is a proxy server (front end) that is distinct from application server (origin/the backend). If the two parse differently then requests may appear to have one header to one server but two to the other, due to slight variations in parser implementation between the two different types of web servers, for example apache and nginx.
The result is that the back end server might treat a malformed HTTP request as two requests, the second of which is usually where an attack is injected. The diagram below demonstrates this where the Blue/Orange square is an attack and sent as a single request, but due to slight differences in how the front end and back end servers serialize/deserialize the requests, the back end server will prepend the attack to the following HTTP request.
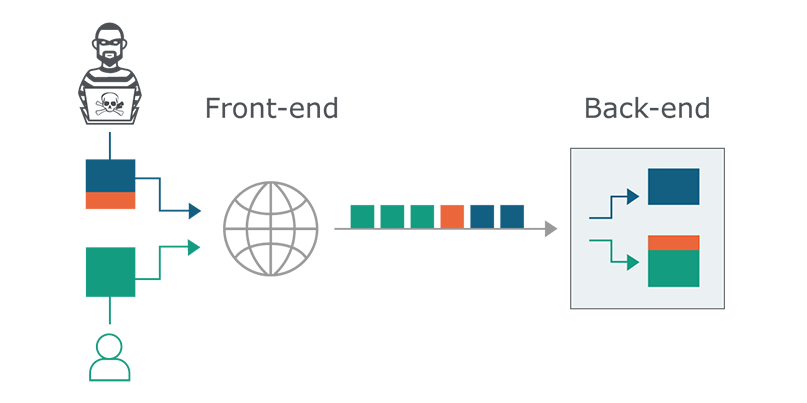
By fiddling around with the attack message, attackers can gather all sorts of metadata by generating error codes, hijacking subsequent normal user requests, and requesting content from other reverse proxy upstream servers / origins.
The implications of this affect almost every CDN company, in fact Akamai is listed as an example of a CDN that was pwned in the white paper.
From a product perspective, the near term practical solution to this is to offer clear disclosures to customers and vendors about how your infrastructure parses content-length and transfer-encoding HTTP headers, so that any mis-alignment of infrastructure can be navigated. Beyond that, vendors could offer customers configurable parsing modules or extensions but that would be very complex. I’m sure there will be many more solutions proposed by the community as this is still a relatively new use of an old exploit.


Leave a comment