This is a summary of ReCAPTCHA v3, which is Google’s free CAPTCHA service. CAPTCHA stands for Completely Automated Public Turing Test To Tell Computers and Humans Apart. A brief summary of Google’s CAPTCHA offerings:
- 1997 – CAPTCHAs invented and deployed at Alta Vista
- 2003 – Another team at CMU claims to invent the CAPTCHA, their version is called reCAPTCHA.
- 2009 – the reCAPTCHA team was acquired by Google and put to work digitizing books for Google Books
- 2011 – Google Books completes digitized all of the NYT Archives and many books
- 2015 – Google releases the noCAPTCHA reCAPTCHA which looked like this:
- 2017 – google released the invisible reCAPTCHA, aka reCAPTCHA v2
- 2018 – Google released another invisible reCAPTCHA, aka reCAPTCHA v3
A simple diagram with call flows::
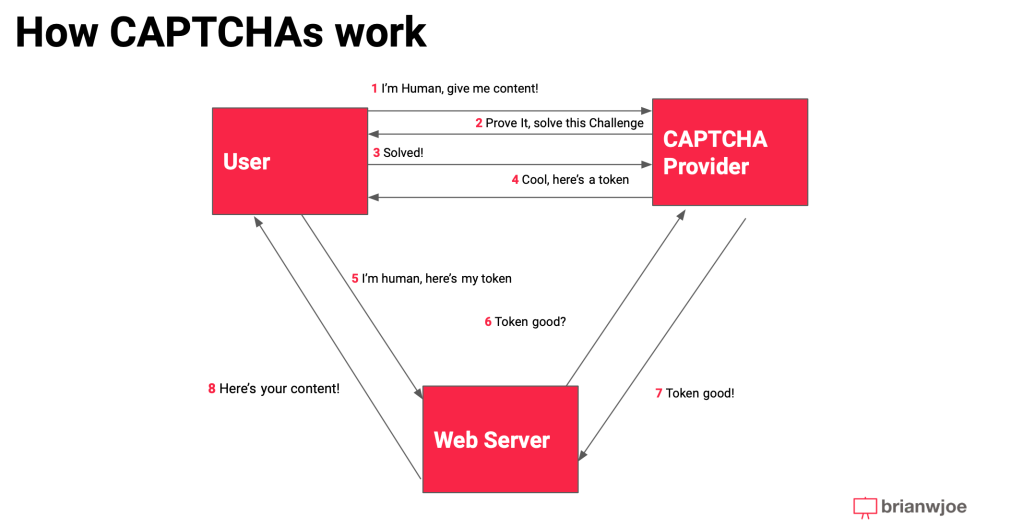
- User goes to a website with a the reCAPTCHA script inserted into the <head> tag:
- The user is shown a Captcha checkbox and can start it by clicking a checkbox
- On user click, a request is sent to Google that includes a site key, a cookie, and a client fingerprint
- The request is analyzed by Google, who is processing these at a scale of 100M per day, who decides what kind of CAPTCHA challenge to the user. There are different types of challenges
- The challenge needs to be answered within 55 seconds, or else the user is required to click on the checkbox again to receive a new challenge.
- When a user successfully solves a challenge, an HTML field in the browser is populated with a token from Google.
- If Google’s backend models believe the user is a human based on fingerprint data and how they solve the CAPTCHA, the token is validated on Google’s backend
- The website validates with Google’s backend the validity of the user using a secret key, the response token, and user IP.
How to exploit this implementation:
One of the weaknesses of reCAPCHA is that much of the fingerprint data can be spoofed using a technique called Canvas Rendering. Another weakness is that valid tokens from one website can be reused by attackers to access another token via a technique called clickjacking.
There are a number of other more detailed methods to get around reCAPTCHA using other techniques, such as AI/ML to actually complete the CAPTCHAs using image classifiers or text recognition. I haven’t spent the time to look into those in detail but my understanding is that that those attacks boil down to economics. Most of them can be defeated, but it costs money. Depending on the target the ROI may or may not be worth it. For example, there are solving services like 2captcha that charge $2.99 per CAPTCHA, which would be worth it against a bank but not a marketing site.


Leave a comment